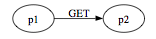
Updated Mar 19, 2007
Static web sites are a collection of HTML files. Dynamic sites like Amazon.com, on the other hand, require that you generate pages on the fly. This essentially means that your site becomes an application instead of a bunch of text files. Your web server must now map a URL to a snippet of executable code that spits out HTML rather than mapping to a file.
In the Java world, you have 2 main choices for executing server-side-Java:
JSP files are enticing at first as they are easier to use than servlets, but they encourage all sorts of bad habits are hard to deal with for large sites.
The best approach is servlets + a template engine. A template engine is usually an MVC (model-view-controller) based scheme where a template (the view) has "holes" it that you can stick values, computed by your business logic (the model). The "holes" are typically restricted to just attribute references or simple computations/loops to avoid re-inventing JSP. The web server + page code executed for a URL embody the controller. There are a million of these engines such as Velocity, FreeMarker, StringTemplate, Tea, ...
To understand why the servlet + template engine approach is superior, it helps to look at the path all developers seem to follow on their way to template engines.
How can you generate HTML from a servlet to send to a client's browser? The obvious first choice is to produce a servlet that uses PrintStream.println() to construct valid HTML and send it to the output stream as in the following example.
public void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException
{
response.setContentType("text/html");
PrintWriter out = response.getWriter();
out.println("<html><body>");
String name = request.getParameter("name");
out.println("Hello "+name);
out.println("</body></html>");
out.close();
}
There are a few problems with this approach.
The problem is that specifying HTML in Java code is tedious, error-prone, and cannot be written by a graphics designer. Shouldn't we invert it so we embed the Java not the HTML? Sounds good; enter JSP:
<html>
<body>
Hello <%=request.getParameter("name")%>
</body>
</html>
Everyone was very excited by in 1999 when this came out as it was really fast to slam out some dynamic HTML pages. Trouble arose, however, when people started building big sites with lots of dynamic pages:
JSP has grown a lot since 1999, but it has not solved the real problem of separating the data model from it's presentation. See below for a discussion of template engines.
Ok, so it's back to servlets then.
Another problem relates to factoring. If all pages are supposed to have the same look, you'll have to repeat all of the print statements such as
out.println("<html><body>");
in each servlet. Naturally, a better way is to factor out this common code. In the OO world that means creating a superclass that knows how to dump the header and footer like this:
public class PageServlet extends HttpServlet {
PrintWriter out;
public Page() {out = response.getWriter();}
public void header(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException
{
response.setContentType("text/html");
out.println("<html><body>");
}
public void footer(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException
{
out.println("</body></html>");
out.close();
}
}
then your servlet would be
public class HelloServlet extends PageServlet {
public void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException
{
header(request, response);
String name = request.getParameter("name");
out.println("Hello "+name);
footer(request, response);
}
}
The second problem relates to design. Is Page a kind of Servlet? Not really. A servlet is merely the glue that connects a web server to the notion of a page that generates output. One could for example reuse the notion of a page to generate output for use in a non-server app that happened to use HTML to display information (e.g., with HotJava java-based browser component).
A better OO design would result in a servlet that creates an instance of a page (solving some threading issues) and invokes its display methods.
Further, you should attempt to isolate your application from the quirks and details of the web server, doing as much as you can in code. You may switch web servers from TomCat to Resin etc... and, in general, you just generally have more control in code than in the server config file. For example, you should do your own page caching as you know better than the web server when data becomes stale.
Here is a generic Page object (decoupled from the details of Servlets except for the request/response objects):
public class Page {
HttpServletRequest request;
HttpServletResponse response;
PrintStream out = ...;
public Page(HttpServletRequest request,
HttpServletResponse response)
{
this.request = request;
this.response = response;
out = response.getWriter();
}
public void generate() {
header();
body();
footer();
}
public void header() {...}
public void footer() {...}
}
A simple hello page might look like this:
public class HelloPage extends Page {
public HelloPage(HttpServletRequest request,
HttpServletResponse response)
{
super(request, response);
}
public void body() {
String name = request.getParameter("name");
out.println("Hello "+name);
}
}
The servlet to invoke a Page object would look like:
public class HelloPageServlet extends HttpServlet {
public void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException
{
Page p = new HelloPage(request, response);
p.generate();
}
}
But, making a servlet for each page is a hassle and unnecessary. It is better to create one servlet with a table that maps URL to Page object. (In the parlance of MVC, your controller is made up of a single Servlet and the Page subclass).
public class DispatchServlet extends HttpServlet {
public void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException
{
String uri = request.getRequestURI();
Page p = lookupPage(uri);
p.generate();
}
public Page lookupPage(String uri) {
if ( uri.equals("/hello") ) {
return new HelloPage(request, response);
}
if ( uri.equals("/article/index") ) {
return new ArticleIndexPage(request, response);
}
...
}
}
Naturally the if-then sequence in lookupPage() method should be coded as a HashMap that maps URI (the non query part of the URL) to a Class object:
public HashMap uriToPageMap = new HashMap();
...
uriToPageMap.put("/hello", HelloPage.class);
uriToPageMap.put("/article/index", ArticleIndexPage.class);
...
Then your doGet() method would use reflection to find the appropriate Page subclass constructor and create a new instance like this:
public void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException
{
String uri = request.getRequestURI();
// which Page subclass does uri map to?
Class c = uriTopageMap.get(uri);
// Create an instance using correct ctor
Class[] ctorArgTypes = new Class[] {
HttpServletRequest.class,
HttpServletResponse.class
};
Constructor ctor = c.getConstructor(ctorArgTypes);
Object[] ctorActualArgs = new Object[] {request,response};
Page p = (Page)ctor.newInstance(ctorActualArgs);
// finally generate output
p.generate();
}
You need to set your web server to map all URLs (but images etc...) to your dispatcher so any /x/y?args lands you in your single servlet. Here is a sample Resin configuration:
<!-- handle special cases that you don't want to hit your dispatcher -->
<servlet-mapping url-pattern='/images/*'
servlet-name='com.caucho.server.http.FileServlet'/>
<servlet-mapping url-pattern='/favicon.ico'
servlet-name='com.caucho.server.http.FileServlet'/>
<servlet-mapping url-pattern='/error.jsp'
servlet-name='com.caucho.jsp.JspServlet'/>
<!-- make your dispatcher handle all others -->
<servlet-mapping url-pattern='/'
servlet-name='DispatchServlet'/>
We are using Jetty though and can modify our Java code to accept anything as a servlet:
ServletHttpContext context =
(ServletHttpContext) server.getContext("/");
context.addServlet("Invoker","/*",
"org.mortbay.jetty.servlet.Invoker");
Now, you have totally isolated your project code from the notion of how pages are requested. You could, for example, build a cmd-line tool that generated pages.
You can also make your Page object handle argument processing and so on. Just add a verify() method:
public class Page {
...
public void verify() throws VerifyException {
// handle default args like page number, etc...
// verify that arguments make sense
// implemented by subclass typically
// VerifyException is a custom Exception subclass
}
public void handleDefaultArgs() {
// handle default args like page number, etc...
pageNum = request.getParameter("p");
}
public void generate() {
out = response.getWriter();
handleDefaultArgs();
try {
verify(); // check args before generation
header();
body();
footer();
}
catch (VerifyException ve) {
// redirect to error page
}
}
}
Your HelloPage could then be augmented as follows:
public class HelloPage extends Page {
...
public void verify() throws VerifyException {
if ( request.getParameter("name")==null ) {
throw new VerifyException("Name argument required!");
}
}
public void body() {
String name = request.getParameter("name");
out.println("Hello "+name);
}
}
Eventually everyone reaches the conclusion that you must separate the code and the HTML template using a template mechanism of some kind in an attempt to make web application development easier, improve flexibility, reduce maintenance costs, and allow parallel code and HTML development.
The mantra of every experienced web application developer is the same: thou shalt separate business logic from display.
One look at the following should give you the idea (taken from a Jetty example):
public void completeSections() {
if ("/index.html".equals(_path)) {
Block _resourceHead = new Block ("div","class=menuRightHead");
_resourceHead.add("Related sites:");
_divRight.add(_resourceHead);
_divRight.add("<div class=\"menuRightItem\"><A HREF=\"http://www.mortbay.com\">"+
"<IMG SRC=\""+_context+"/images/mbLogoBar.gif\" WIDTH=120 "+
"HEIGHT=75 ALT=\"Mort Bay\"></A></div>");
_divRight.add("<div class=\"menuRightItem\">"+
"<A HREF=\"http://sourceforge.net/projects/jetty/\">");
if (__realSite)
_divRight.add("<IMG src=\"http://sourceforge.net/sflogo.php?group_id=7322\""+
"width=\"88\" height=\"31\" border=\"0\" alt=\"SourceForge\">");
else
_divRight.add("<IMG SRC=\""+_context+"/images/sourceforge.gif\""+
" WIDTH=88 HEIGHT=31 BORDER=\"0\" alt=\"SourceForge\"></A>");
_divRight.add("</A></div>");
...
These enticing benefits derive entirely from a single principle: separating the specification of a page's business logic and data computations from the specification of how a page displays such information. With separate encapsulated specifications, template engines promote component reuse, pluggable, single-points-of-change for common components, and high overall system clarity.
I have discussed the principle of separation with many experienced programmers and have examined many commonly-available template engines used with a variety of languages including Java, C, and Perl. Without exception, programmers espouse separation of logic and display as an ideal principle. In practice, however, programmers and engine producers are loath to enforce separation, fearing loss of power resulting in a crucial page that they cannot generate while satisfying the principle. Instead, they encourage rather than enforce the principle, leaving themselves a gaping "backdoor" to avoid insufficient page generation power.
Unfortunately, under deadline pressure, programmers will use this backdoor routinely as an expedient if it is available to them, thus, entangling logic and display. One programmer, who is responsible for his company's server data model, told me that he had 3 more days until a hard deadline, but it would take 10 days to coerce programmers around the world to change the affected multilingual page displays. He had the choice of possibly getting fired now, but doing the right thing for future maintenance, or he could keep his job by pushing out the new HTML via his data model into the pages, leaving the entanglement mess to some vague future time or even to another programmer.
The opposite situation is more common where programmers embed business logic in their templates as an expedient to avoid having to update their data model. Given a Turing-complete template programming language, programmers are tempted to add logic directly where they need it in the template instead of having the data model do the logic and passing in the boolean result, thereby, decoupling the view from the model. For example, just about every template engine's documentation shows how to alter the display according to a user's privileges. Rather than asking simply if the user is "special", the template encodes logic to compute whether or not the user is special. If the definition of special changes, potentially every template in the system will have to be altered. Worse, programmers will forget a template, introducing a bug that will pop up randomly in the future. These expedients are common and quickly result in a fully entangled specification.
A template should merely represent a view of a data set and be totally divorced from the underlying data computations whose results it will display.
Many template engines have surfaced over the past few years with lots of great features. I built an engine called StringTemplate that not only has many handy features but that strictly enforces separation of model and view.
The trick is to provide sufficient power in a template engine without providing constructs that allow separation violations. After examining hundreds of template files used in my web sites, I conclude that one only needs four template constructs:
This discussion is pulled almost verbatim from my formal treatment of strict model-view separation and template engines.
You can look at the collection of pages in a website as a graph with the pages representing nodes and http GET, POST methods representing edges. Further, you can see this graph (or network) as a simple finite state machine (FSM).
You could represent graphically the link from page p1 to page p2 as:
Similarly a button on, say page edit_msg, whose enclosing <form> tag target is process_edit might look like:
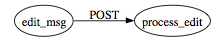
Pages can perform redirections via HttpServletResponse.redirect(url), which you can represent as:
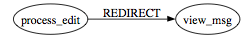
Your processing pages should always compute and redirect to another page, never leaving the browser pointing to a processing page. Aside from revealing internal details (people seem to love to try random combinations of URL arguments to screw up your site), it allows a browser "REFRESH" to execute that code again and again (for example, purchasing the same airline ticket n times).
The complete forum message edit/view FSM might look like:

Because not all pages are reachable from every other (directly or indirectly), you actually have a collection of subgraphs or FSMs.
Building diagrams for all your processing FSMs is extremely useful design-wise and for documentation purposes. For example, here is a decent start on your web mail project:
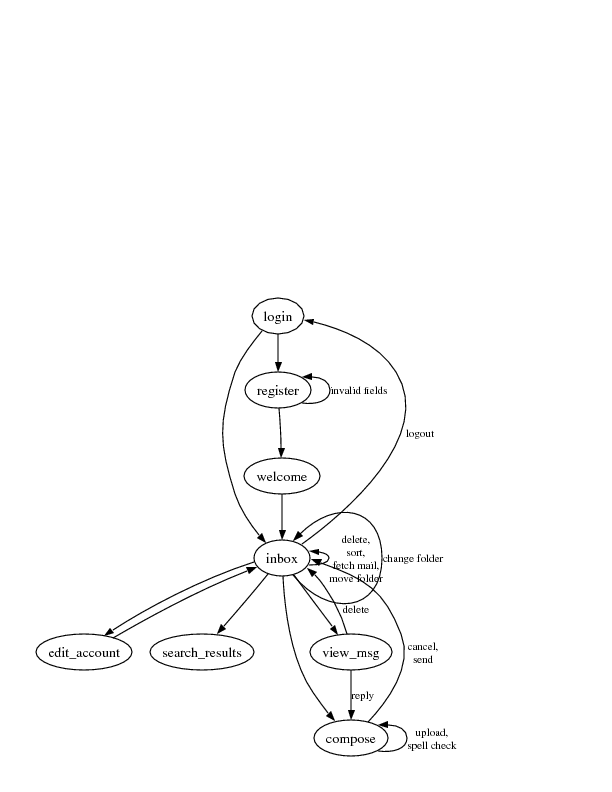
One of the problems introduced by page based HTML interfaces is that the natural thing to do is group your code according to the pages (i.e., the browser page transitions) rather than the "task" or "operation". Hence, we put edit-faq processing code in a separate spot than the edit-faq display code. Complicated processing sequences such as seen at airline ticket purchasing sites are further scattered across multiple processing pages. Your code quickly becomes unmanageable and you don't know who invokes which page.
It is really irritating that you need to build a complete page and any associated Java class just to execute a single line of processing code. This page would execute in response to a GET (link) or POST (submit button). For example, if there is a hide button on a forum view page, you typically need to create a separate page called process_hide or whatever to handle the event.
Aside from being irritating, this separation breaks encapsulation, making it hard to figure out how page events are processed (you have to look at two pages in separate class files). This separation is the source of many "disconnect" errors between <form> field names on one page and getParameter(name) requests on the other (processing) page.
After years of experimentation, I have found a useful way of encapsulating a page with its processing code. The idea is to jump to the same page for processing, but with an event.eventname argument in the URL. Every page/node has an implicit "view" action that generates the desired HTML and also has "state transition" (event processing) actions that react to events emanating from the view such as POST events.
The presence of an event.eventname argument directs the Page.service() method to invoke a processEvent(eventname) method instead of the usual displayBody() method of your page. For example, the view might generate HTML code to allow POST events such as:
... <form action=same-page-you-are-looking-at method=POST> ... <input type=image src="/images/buttons-verify.gif" name="Event.verify"> <input type=image src="/images/button-cancel.gif" name="Event.cancel"> </form> ...
In this manner, you can look at each page as having a "view" (the default action) and one or more "event" actions. The important thing is that all code to view/process is in one class. This is great for the following reasons:
The general code development strategy for web-based processes should be to encapsulate code related by process or subprocess. Don't be tempted to let artificial external execution-related constraints such as "I have to move to another page to get code to execute" affect how you group viewing and processing code.
Many processing pages need to execute some code and jump immediately back to the "invoking" page. Because there is really no notion of a stack of pages, there is no notion of an invoking page. You can create a stack, however. For example, the process_edit page wants to redirect back to the view_msg page. If you have a stack, you push the current page onto the stack at each page view. Then "returning" is a simple matter of popping the previous page off and doing a redirect() to it.
| NOTE: This scheme breaks down when you consider the fact that if a user has two browser windows open, a single stack per user cannot track pages properly. The stack gets jumbled up with pages from both browser requests. Unfortunately, there is no way to automatically distinguish between browser windows. |
The easiest way to deal with this problem is to encode an argument returnURL in each link on your site. If you have factored your code well and use a single method to compute a link on your site, the method can automatically encode this argument. Then your default argument processing can intercept this argument and provide it to a processing page. For example, you would set up an edit link from the forum view page similar to the following:
/forums/edit_msg?ID=243&returnURL=/forums/view_msg%3FID%3D243
where %3FID%3D4 is the encoded version of ?ID=243. Here is what the Java code might look like:
class ProcessEdit extends Page {
...
public void verify() throws VerifyException {
super.verify(); // Page.verify() handles returnURL arg
if ( request.getParameter("subject")==null ) {
throw new VerifyException("missing arg subject");
}
...
}
public void body() {
// here is where you execute code
// ... update the database
// don't display anything, redirect to invoking page
String url = getReturnURL(); // set by Page.verify();
response.redirect(url);
}
}
Many web servers are readonly for the most part because people are not posting content constantly; usually they are reading pages. This makes it pretty easy to simply load up all the data in the system upon startup. The database is a persistent store not the place where we constantly get data therefore. You should write through the cache, however, so that new posts get cached and stored in the database.
Even if you think you can get data very quickly from the database, you can't beat pulling data from memory. A quick 10ms db access does not scale. If you have 5 refs per page, you're up to 50ms per page. If you have 10 users hitting a page per second, you delay each page by .5 seconds. If you have 100 refs on some index page, you're doing 100x10sm=1second for a single user. This does not scale.
Putting SQL commands directly in your page objects (whether, servlets, JSP, ASP, etc...) is not only slow as hell, but represents a serious maintenance problem. Your database schema will change and so will other higher-level business logic specifications. Your goal should be to encapsulate logic and persistent store requests into your model.
If your database fits easily in memory, you would be wise to simply load all data into memory (making sure to save all new data to the database and update your cache).
During the edit-view cycle, your application must track temporary data, such as forum subject/message, as it weaves its way through the various nodes of the FSM graph. You can either keep passing temporary data as parameters between nodes or you can store the data in a Java object visible to each page of a specific FSM associated with a process like edit/view forum. Passing arguments works well for 2 pages, but for multi-page sequences like buying an airline ticket, you need real temporary data persistence in the server.
If you have formalized each processing sequence as a FSM, such as ForumEditViewMachine, then you can simply define instance variables subject and message and all pages defined for that FSM can see or set the data. You must augment your FSM controller to be able to return the same machine object as a user walks through the pages of a FSM.
Unless you formalize this mechanism somehow (doesn't have to be a FSM), you will produce a series of pages that manipulate data in a totally inconsistent manner. Maintenance of these processes suffers without consistency.
Don't make your error message page part of your application. That's a good way to get your server into an infinite loop as it continuously redirects to itself. Make a simple JSP page that has the same look as your site and accepts an error message parameter that it prints out.
One of the annoying problems with an HTML browser interface to your server involves multiple browser windows opened by the user sending/receiving data to your web site. If you store temporary working data on a per user basis, your user can only perform one operation such as forum edit/view at once. It is not uncommon for a user to open two browser windows to your site and try to edit two different forum entries simulatenously. The user will see really bizarre things like data from the window one magically appear in window two!
Because you have no way to identify from which browser window the user submits data, you must encode something in the URL. The only solution that I have come up with is to encode an operation key, "opkey", in the URL so that you store temporary working data associated with processes by user and opkey. To make this work, you must generate dynamic links to your process entry pages rather than static links. In other words, instead of
<a href="/forum/edit.jsp?ID=234">edit this entry</a>
you must use a template such as
<a href="/forum/edit?ID=234&opkey=$opkey$">edit this entry</a>
where $opkey$ is continuously changed upon every page view.
The user would see the edit link with opkey=1 the first time they visit a page. If they open a new window (or hit refresh in the same window) to the same page, they would see the same edit link but with opkey=2 or some other number. In this way, multiple browsers begin the edit-view process with different opkeys. With a different opkey, your server knows which temporary data to use; it would keep multiple copies of the working data per user, one for each opkey.
Note that this really screws up your page caching. I.e., this makes caching the whole page impossible.