Due date: Mar 26, 2007
Note: I may have to update the project as details/issues arise. [Updated March 18, 2007]
Takes between 10 and 25 hours to complete.
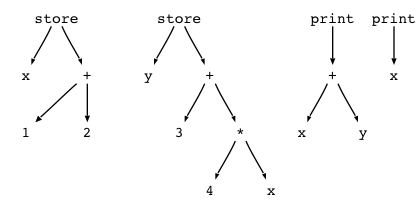
Your goal in this project is to build a simple programming language interpreter and compiler. The programming language has assignments and print statements. Here are some sample statements:
x=1+2 print x y=3+4*x print x+y
You will build an expression tree implementation that can be used by the parser that I provide. The parser will build trees that look like the following for the above input (slightly out of order):
Each node in the tree will have a different type. For example, the first assignment subtree would have the following Java node types:
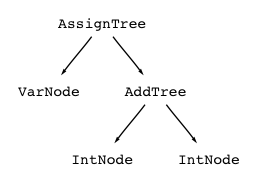
The trees are binary trees and therefore have at most two children. Each node also has an optional payload, which in our case, points at a Token object. That object will contain the token type and text of the input symbol. So, for input symbol xyz, the associated token has type ID and text "xyz". Some nodes, such as AddNode, do not have payloads because it's obvious what the input symbol is.
Your base implementation will be in BinaryTree.java within package trees and must implement the methods shown below:
package trees;
public class BinaryTree {
/** Generic payload for this tree node; Token in our case though */
public Object payload;
/** The two children. If only one child, then set left not right ptr. */
... declaration missing ...
public BinaryTree(Object payload) {
this.payload = payload;
}
/** Recursively walk the tree to find max height from root to leaf.
* An empty tree has size 0, a single node has height 1.
*/
public int height() {
...
}
/** Return a string in format: (root child1 ... childN) with a
* space in between elements. Use this.toString() to print
* each node. E.g., "print x+y" yields:
* "(trees.PrintTree (trees.AddTree x<ID> y<ID>))"
*/
public String toStringTree() {
...
}
/** Return a string for this node only. If payload is not null,
* return payload.toString() else return getClass().getName().
*/
public String toString() {
...
}
}
All of your classes will be in the trees package; be careful when packaging up the jar file.
Once you have the basic binary tree implementation, you need to build a subclass called ExpressionTree:
package trees;
public abstract class ExpressionTree extends BinaryTree {
/** Evaluate the subtree and return the integer result;
* all subclasses implement.
*/
public abstract int eval(Interp interpreter);
/** Compute bytecode(s) for this tree; all subclasses implement. */
public abstract void gen(CodeGen generator);
/** How many nodes of type VarNode are there in the tree? You can
* use the instanceof operator.
*/
public int countVarNodes() {
...
}
}
You need to implement countVarNodes() in that method and then create a number of subclasses that implement eval() and gen():
AddTree.java AssignTree.java IntNode.java MultTree.java PrintTree.java VarNode.java
You will need to look at the Parser.java to figure out what constructors you need for the various classes.
Method eval() is for the interpreting the tree and gen() is for generating bytecodes from the tree.
You must implement an interpreter that executes the trees, which amounts to implementing eval() for each ExpressionTree subclass. Given the above input, your tree implementation must be such that the parser Interp program emits:
$ java tool.Interp < input (trees.AssignTree x<ID> (trees.AddTree 1<INT> 2<INT>)) (trees.PrintTree x<ID>) 3 (trees.AssignTree y<ID> (trees.AddTree 3<INT> (trees.MultTree 4<INT> x<ID>))) (trees.PrintTree (trees.AddTree x<ID> y<ID>)) 18 $
The Interp object accepts an input stream, such as standard input, and then tells the interpreter to execute:
Interp interpreter = new Interp(System.in); interpreter.execute(); System.out.println(interpreter.out);
The parser (method prog()) returns a List of subtrees found by rule stat. The interpreter's execute() method then prints the tree and calls eval() on each subtree.
ExpressionTree t = (ExpressionTree)statements.get(i);
out.append(t.toStringTree());
out.append("\n");
t.eval(this);
Naturally, you have to implement toStringTree() in BinaryTree.
To do the interpretation, each node implementation will have an eval() method. The eval() method takes a pointer to the Interp object that is executing the associated tree. This is how you can access the variables and out fields. The variables map tracks the value assigned to each variable computed during assignment statements. The out buffer is where the interpreter (and likewise the compiler) will emit output.
You will implement IntNode's evaluation as follows:
public int eval(Interp interpreter) {
Token t = (Token)payload;
return Integer.parseInt(t.text);
}
VarNode will execute by pulling the value out of the hash table for the text of token stored in that node.
There are two kinds of statements, assignment and print statements.
AddTree will evaluate the left child and the right child, add the result, and return it.
MultTree will evaluate the left child and the right child, multiply the result, and return it.
Assignment subtrees evaluate the expression from the right child and store it into the variable from the left child. You will store these values in the hash table called variables. Statements such as assignments do not return a value from eval(). For x=expr, map x to the value of expr.
To execute the print subtree, simply evaluate the left child and then append the value (and a newline) to the out field of the Interp object. Statements such as print do not return a value from eval().
You will build a simple compiler by implementing gen() for each ExpressionTree subclass. Your program must emit the following bytecodes for the above input file :
; public class Calc extends Object { ...}
.class public Calc
.super java/lang/Object
; public Calc() { super(); } // calls java.lang.Object()
.method public <init>()V
aload_0
invokenonvirtual java/lang/Object/<init>()V
return
.end method
; main(): you will generate bytecode for this method
.method public static main([Ljava/lang/String;)V
.limit stack 4 ; I use your height() method to compute this
.limit locals 3 ; I use your countVarNode() method to compute this
;
; START OF WHAT YOU EMIT (you don't have to emit the comments)
;
; x = 1+2
ldc 1
ldc 2
iadd
istore 1 ; store in first local variable
; print x
getstatic java/lang/System/out Ljava/io/PrintStream;
iload 1
invokevirtual java/io/PrintStream/println(I)V
; y = 3+4*x
ldc 3
ldc 4
iload 1
imul
iadd
istore 2 ; store in second local variable
; print x+y
getstatic java/lang/System/out Ljava/io/PrintStream;
iload 1 ; load first local variable
iload 2 ; load second local variable
iadd
invokevirtual java/io/PrintStream/println(I)V
;
; END OF WHAT YOU EMIT
;
return
.end method
The parser automatically knows how to spit out the bytecode header and footer. See Parser.header field etc... All you have to do is figure out how to generate byte code instructions for the expressions and statements. Your gen() methods should append code to the out field of the CodeGen object.
The main() method of CodeGen asks a CodeGen object to compile then emit output:
CodeGen generator = new CodeGen(System.in); generator.compile(); generator.emit();
The compile() method calls gen() for each subtree return from the parser prog() method:
ExpressionTree t = (ExpressionTree) statements.get(i); t.gen(this);
Using the command-line, you can redirect the output to a file:
$ java tool.CodeGen < input > input.j $
File input.j will contain the above bytecode assembly, which you will translate to a .class file using jasmin (see below also):
$ java -jar /home/public/cs245/jasmin.jar input.j Generated: Calc.class $
Then of course you just run it like normal Java:
$ java Calc 3 18 $
The trees are not printed as they are with the interpreted version of this program.
The Java virtual machine is a stack machine instead of a register machine (like an x86 box). Operands are placed on the stack and operations pop operands from the stack, pushing the result back on. Local variables and parameters are also stored on the stack. The main() method has one argument, String args, at index 0 upon entry. Any local variables that we need will be therefore at index 1 and above. That is, the first local variable is that index 1, the second local variable is at index 2, and so on. To store the value 33 in the first local variable execute:
; x = 33 where x is local variable 1 ldc 33 ; push constant 33 onto the stack istore 1 ; store integer from top a stack into the 1st local variable
The interpreter above stored the value of a variable in a hash table variables. Instead, the compiler stores the variable number, assigning them in the order seen. For example,
x = ... y = ...
defines two local variables at indexes 1 and 2. The variables map would have [x:1, y:2] in it.
To make all of this more concrete, here is the implementation of gen() for IntNode that emits code properly.
public void gen(CodeGen generator) {
Token t = (Token)payload;
generator.out.append(" ldc "+Integer.parseInt(t.text)+"\n");
}
All you need are a few instructions to do this project; they are summarized in the next section.
| instruction | description |
| ldc c | Push a constant integer onto the stack. |
| iadd | Add top two integers on stack and leave result on the stack. Executes push(pop+pop). |
| imul | Multiply top two integers on stack and leave result on the stack. Executes push(pop*pop). |
| istore local-var-num | Store top of stack in local variable and pop that element off the stack. |
| iload local-var-num | Push local variable onto stack. Stack depth is one more than before the instruction. |
| getstatic object object-type-sig | Load the static (class variable) object onto the stack with the specified type. |
| invokevirtual method-sig | Invoke the method specified. |
You don't really have to understand the last two instructions. Just know that when you want to generate code for the print statement, you need to emit the following instructions:
; compiled code for "print expr" ; get System.out on stack getstatic java/lang/System/out Ljava/io/PrintStream; ...compute-expr-leaving-on-stack... ; invoke println on System.out (object 1 below top of stack) invokevirtual java/io/PrintStream/println(I)V
You need to convert bytecode assembly code (text) to a binary .class file using jasmin:
$ java -jar /home/public/cs245/jasmin.jar input.j Generated: Calc.class
where input.j is some bytecode file. This produces a file called Calc.class because that is the surrounding class definition I have provided for you.
My parser implements the following grammar:
prog : stat+ ;
stat : ID '=' expr newline
| 'print' expr newline
;
expr : mexpr ('+' mexpr)* ;
mexpr : primary ('*' primary)* ;
primary : INT | ID;
The syntax looks like
rulename :
alternative-1
| alternative-2
...
| alternative-n
;
Where (...)* means zero-or-more and stat+ means one-or-more stat invocations.
I have provided some initial unit tests in TestInterp and TestCodeGen (package test). You must add more tests so you know if your code works. We will run these tests as well as testing your code using standard input. Unit tests are 10% of your grade. I am testing you on your ability to figure out what tests to do. The unit tests look like:
public void testAssign() throws Exception {
String input = "a=34\n";
Interp interpreter = new Interp(new StringBufferInputStream(input));
interpreter.execute();
String expecting =
"(trees.AssignTree a<ID> 34<INT>)\n";
String found = interpreter.out.toString();
assertEquals("testing single int", expecting, found);
}
Here is the parser and invoking interpreter and compiler main programs.
You have the necessary junit lib in /home/public/cs245/junit.jar.
For your entertainment and education, you should read all the parser code.
You must turn in the following classes:
Put the source and .class files for these Java classes into tree.jar. Note that you must run jar from the directory containing tool, test, trees, and parser directories; for example:
$ cd ~/cs245/proj3 $ ls parser test tool trees $ jar cvf /home/submit/cs245/userid/tree.jar . ...
For the mid-release, this time, don't print your code. Just put up your jar file into /home/submit/cs245/userid.
For the final release of this project, I need your final printout of your trees package code, but not my parser directory code nor main programs.
You will submit a jar file called tree.jar containing source and *.class files into the submit directory:
/home/submit/cs245/userid
(Use Java 1.5 or lower to compile your classes). For example, I would submit my project as file:
/home/submit/cs245/parrt/tree.jar
We will run your program via
$ java -cp ".:/home/submit/cs245/userid/tree.jar" tool.Interp < input ...
and
$ java -cp ".:/home/submit/cs245/userid/tree.jar" tool.CodeGen < input > input.j $ java -jar /home/public/cs245/jasmin.jar input.j Generated: Calc.class $ java Calc ... $
For the unit tests, we'll do this:
$ java -cp "/home/public/cs245/junit.jar:/home/submit/cs245/userid/tree.jar" \
junit.textui.TestRunner test.TestInterp
..
Time: 0.017
OK (2 tests)
$ java -cp "/home/public/cs245/junit.jar:/home/submit/cs245/userid/tree.jar" \
junit.textui.TestRunner test.TestCodeGen
..
Time: 0.017
OK (2 tests)
We will assign points as follows:
| points | what |
| 5 | mid-project release Wed Mar 21st (submit jar) |
| 5 | Overall code style and cleaniness |
| 10 | unit tests |
| 10 | BinaryTree.height() |
| 10 | BinaryTree.toStringTree() |
| 6 | ExpressionTree.countVarNodes() |
| 5 | AddTree.eval() |
| 5 | AssignTree.eval() |
| 5 | IntNode.eval() |
| 5 | MultTree.eval() |
| 5 | PrintTree.eval() |
| 5 | VarNode.eval() |
| 4 | AddTree.gen() |
| 4 | AssignTree.gen() |
| 4 | IntNode.gen() |
| 4 | MultTree.gen() |
| 4 | PrintTree.gen() |
| 4 | VarNode.gen() |
| 100 | Total |
Note: Style includes how clean the code is, how well you comment, how good the method and variable names are, whether you have removed all your debugging print statements, removed commented-out dead code, etc...
5 points off if your jar is messed up or your classes or have wrong case etc... I.e., anything that prevents us from being able to run your library "out of the box".
Reminder: There is no such thing as a late project; late projects get a zero score. Projects are due the instant class starts at 9:40 a.m. and your jars must be in the submit directory.