Dynamo: Amazon's Highly Available Key-value Store
Authors: DeCandia, Hastorun, Jampani, Kakulapati, Lakshman, Pilchin,
Sivasubramanian, Vosshall, and Vogels
Overview
- Amazon's platform is comprised of many different services with varied
characteristics
- Shopping carts, customer preferences, product catalog
- Reliability and scalability are critical
- Customers will take their business elsewhere if they don't get the
service they expect
- Millions of components work together to provide Amazon's service using
a highly decentralized, loosely coupled, service oriented
architecture
- Google also uses this model of building reliable software to run on
commodity PCs
- Bottom line: failure is the norm
- Dynamo's focus: providing primary-key access to a data store
- Sufficient for many services like shopping carts, customer
preferences
- RDBMS is too much and doesn't allow consistency/availability
tradeoff
- Uses eventual consistency (lazy replication/gossiping) to trade
consistency for availability
System Design
- Query Model: DHT-like semantics. A data item (blob) is identified by a
key.
- ACID Properties: Trade consistency for availability. No isolation
guarantees are provided.
- Efficiency: Example SLA: provide a response within 300ms for 99.9%
of its requests for a peak client load of 500 requests per
second.
- Assumptions: The environment is non-hostile.
- Key Design Choices:
- Increase availability using optimistic replication
- Data store is always writable -- conflict resolution happens during
reads
- Application can perform conflict resolution
- Incremental scalability
- Symmetry - nodes have same responsibilities
- Decentralization
- Heterogeneity
System Architecture
- Operations supported are
get and put
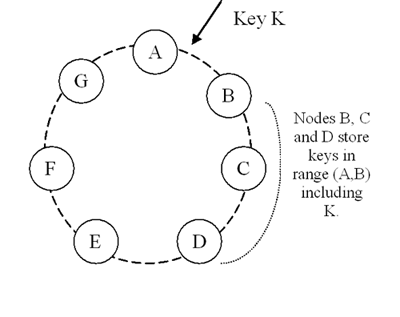
- Each node is assigned an ID in a Chord-like circular ID space (chosen
randomly from the ID space)
- Each key is hashed using MD5 to generate an ID
- Data with ID id is stored at node n with ID
successor(id) (in Chord terminology)
- Data is replicated at N-1 successors of n
- Nodes responsible for storing a particular key are its
preference list
- e.g., Node D below stores (A, B], (B, C], and (C, D]
- Image at:
http://s3.amazonaws.com/wernervogels/public/sosp/sosp-figure2-small.png
Membership and Failure Detection
- An administrator uses a command-line or browser-based tool to
add/remove nodes
- The tool contacts a node, provides it with the new membership
information, and the node writes the info to persistent storage
- Every second, each node randomly chooses another node and exchanges a
view of the membership
- At startup, nodes choose their token sets (IDs) and this partitioning
information is also exchanged via the gossiping protocol
- If a new node, e.g., X inserted between A and B in the figure above,
joins and becomes responsible for a set of keys, its successors (e.g, B,
C, and D) will pass off the appropriate set of their keys to the new
node
- Each node knows the token ranges handled by the other nodes and can
forward requests directly
- To avoid partitioning, all nodes know about a set of seeds and
exchange membership information with them
- Failure is detected when a node fails to respond to communication
- Because data is replicated, a failed node does not impact system
behavior
get/put Operations
- A request is routed to a coordinator using a generic load
balancer or partition-aware client
- The coordinator is one of the top N nodes in the preference list
- To meet SLAs a write coordinator is usually chosen as the node that
replied fastest to a prior read (assumes writes typically follow
reads)
- A quorum-like system is used to ensure that R replicas participate in a
successful read and W replicas participate in a successful write (where R
and W are configurable parameters)
- The coordinator replies that a get is successful if R replicas respond,
and a put is successful if W replicas respond
- Lower values for R and W provide better latency, but worse
consistency
Versioning
- A get may produce several versions of the same object
- e.g., the latest write did not propagate to a replica that
responded to a subsequent read
- Vector clocks are used to keep versioning information
- Image at:
http://s3.amazonaws.com/wernervogels/public/sosp/sosp-figure3-small.png

- When a client does a put, it must specify which version it is
updating
- If a get results in multiple versions, the client must reconcile
Implementation and Evaluation Discussion
- Typically, N=3, R=2, and W=2
- Experiments were run on a couple hundred nodes
- The system is configured so that data is replicated across nodes at
different data centers
- Divergent Versions: an experiment looked at the shopping cart service
over a 24 hour period
- 99.94% of requests saw 1 version
- .00057% saw 2 versions
- .00047% saw 3 versions
- .00009% saw 4 versions
- Does this system scale?
Sami Rollins
Wednesday, 07-Jan-2009 15:13:20 PST
Wednesday, 07-Jan-2009 15:13:20 PST